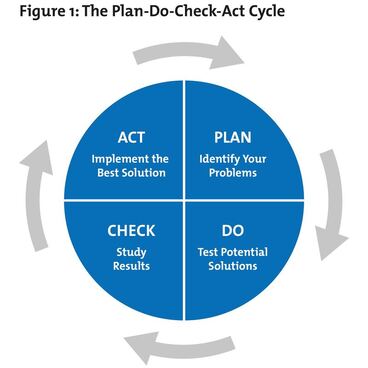
 Figure 1 - PDCA Model courtesy of The W. Edwards Deming Institute®. Figure 1 - PDCA Model courtesy of The W. Edwards Deming Institute®. Identifying a model or strategy to apply to produce maximum positive results is imperative. Consider our research is centered on emerging and existing technologies integrating the best processes. To optimize outcomes, the authors recommend a strategic framework in which to operate within. Below are two models many industrial and systems engineers will be familiar with, the PDCA and CRISP-DM. The third component is a focus on governance of data, configuration management, certification of data structures, and processes around presenting the integrity of the data science practice. The Plan, Do, Check, Act (PDCA) model is a suitable framework in which to manage solutions for business process, optimization, and platforms. Originating with Dr. William Edwards Deming in the 1950’s, the PDCA model gives us a continuous feedback loop. The “planning” phase centers on problem definition and identifying the data sources required, and affected processes. In the “do” phase, we build and deploy the solution. This may be a limited pilot, minimal viable product, prototype, or phased deployment with limited production impact. In the “check” phase, we assess the expectations, early results and have the opportunity to adjust. Many call this the “study” phase where we apply new techniques, alter the approach. Finally, the “act” phase completes the deployment and sets the new baseline. All four phases of the PDCA model have a continuous feedback loop to improve outcomes. 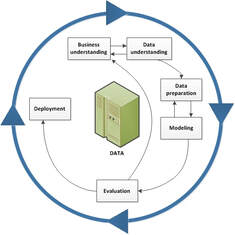 Figure 2 CRISP-DM Model Courtesy of IBM Figure 2 CRISP-DM Model Courtesy of IBM The CRISP-DM, which stands for Cross-Industry Standard Process for Data Mining, is an industry-proven way to guide data mining efforts. It combines business understanding, data understanding, data preparation, modeling, evaluation and deployment. The CRISP-DM model can be tailored and fit for use. Its strengths include a focus on business comprehension and how respective data sets align to business processes. It also identifies potential data specific problems such as missing data, error types, measurement errors, coding dependencies and inconsistencies, as well as metadata mismatches.
Governance of the data, data structures, models, and runs will be required for preserving integrity of the solution over the life cycle of the system. One key characteristic of the governance model should be a “data lineage” feature to track the source data across languages, file systems, databases, platforms. While the discipline of data governance is new to many organizations, it is particularly well-suited for industrial and systems engineers to define the process, lean it out, and provide measurable insights.
0 Comments
Leave a Reply. |
 AuthorDirector 
Archives
January 2023
Categories
All
|
 RSS Feed
RSS Feed
Photos from europeanspaceagency, ▓▒░ TORLEY ░▒▓, Lori_NY, Dean_Groom, dalecruse, Fin Cosplay & Amigurumi, Iain Farrell, erin_everlasting, palindrome6996, Easa Shamih (eEko) | P.h.o.t.o.g.r.a.p.h.y, markhillary, Matt McGee, Marc_Smith, woodleywonderworks, agustilopez, rachel_titiriga, SeaDave, cheri lucas., Caio H. Nunes, grabbingsand, Armchair Aviator, quinn.anya, Jennifer Kumar, billaday, edtechworkshop, chucknado, purpleslog, yugenro, christianeager, dground, GlasgowAmateur, expertinfantry, shixart1985 (CC BY 2.0), OiMax, Wilfried Martens Centre for European Studies, PEO, Assembled Chemical Weapons Alternatives, IBM Research, shixart1985, markus119, shixart1985, shixart1985, Wilfried Martens Centre for European Studies
